T-Retriever: Tree-based Hierarchical Retrieval Augmented Generation for Textual Graphs
Chunyu Wei1 Huaiyu Qin1 Siyuan He1
Yunhai Wang1 Yueguo Chen1
1Renmin University of China
Accepted by The 40th Annual AAAI Conference on Artificial Intelligence
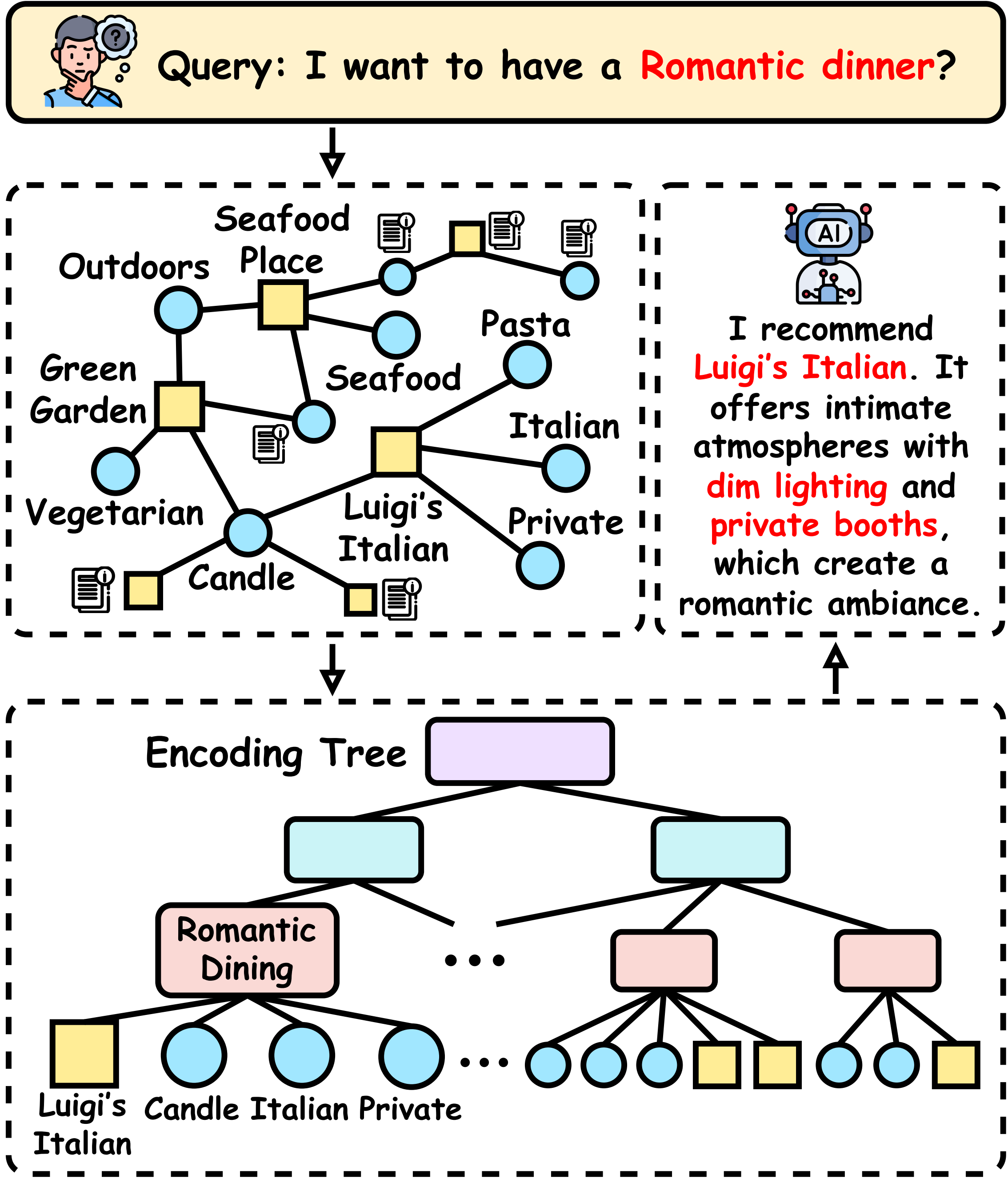
Figure 1: Illustration of T-Retriever. Hierarchical organization of attributed graph knowledge enabling effective multi-resolution context retrieval for question answering.
Abstract:
Retrieval-Augmented Generation (RAG) has significantly enhanced Large Language Models' ability to access external knowledge, yet current graph-based RAG approaches face two critical limitations in managing hierarchical information: they impose rigid layer-specific compression quotas that damage local graph structures, and they prioritize topological structure while neglecting semantic content. We introduce T-Retriever, a novel framework that reformulates attributed graph retrieval as tree-based retrieval using a semantic and structure-guided encoding tree. Our approach features two key innovations: (1) Adaptive Compression Encoding, which replaces artificial compression quotas with a global optimization strategy that preserves the graph's natural hierarchical organization, and (2) Semantic-Structural Entropy (S²-Entropy), which jointly optimizes for both structural cohesion and semantic consistency when creating hierarchical partitions. Experiments across diverse graph reasoning benchmarks demonstrate that T-Retriever significantly outperforms state-of-the-art RAG methods, providing more coherent and contextually relevant responses to complex queries.
Source Code: https://github.com/T-Retriever/T-Retriever
Figures:
Figure 2: The T-Retriever framework pipeline: (1) Encoding Tree Construction optimizes S²-Entropy (combining structural and semantic information) through partition, prune, and regulate operations; (2) Indexing generates and embeds LLM-based summaries for tree nodes; (3) Tree Retrieval finds relevant nodes, extracts subgraphs, and generates responses using GNN-enhanced LLM prompting.
Figure 3: Sensitivity analysis of key hyperparameters. (a-c) Impact of encoding tree layers $L$ and retrieved subgraphs $k$ across different datasets. (d) Impact of the entropy weighting factor $\lambda$ on WebQSP.
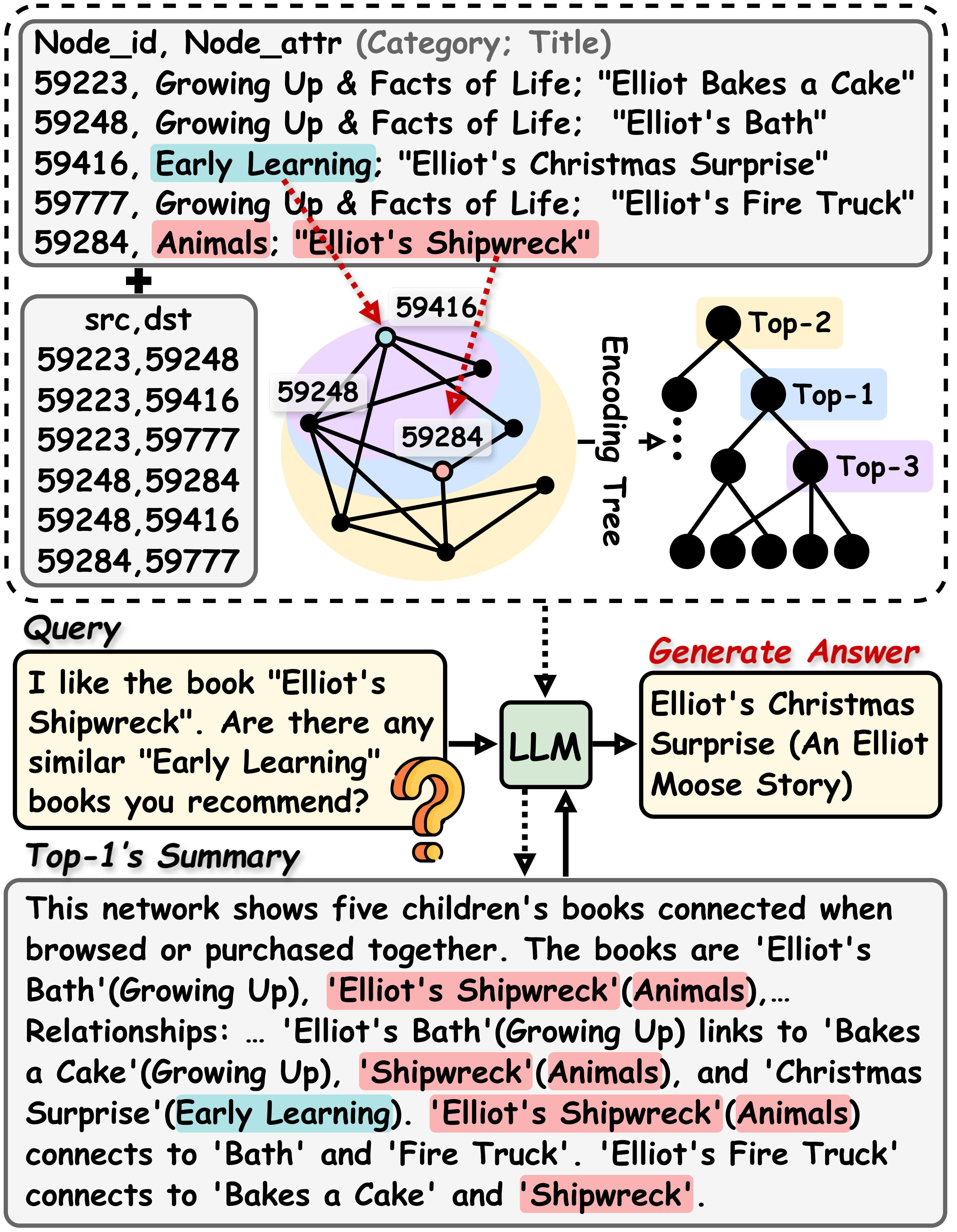
Figure 4: Case study visualization from BookGraphs.
Materials:
 |
| Paper (965k) |
Acknowledgements:
This work was supported by The Disciplinary Breakthrough Project of Ministry of Education (MOE,#00975101), NSFC (No.6250072448, No.62272466, U24A20233), and Big Data and Responsible Artificial Intelligence for National Governance, Renmin University of
China.