Ramba: Selective State-Space Models for Relational Deep Learning
Yiming Liu1
Chunyu Wei1
Haozhe Lin2
Fengjun Xiao3
Junqi Zhang4
Yunhai Wang1
Yueguo Chen1
1Renmin University of China
2Tsinghua University
3Hangzhou Dianzi University
4Beijing University of Technology
Accepted by ICML 2026
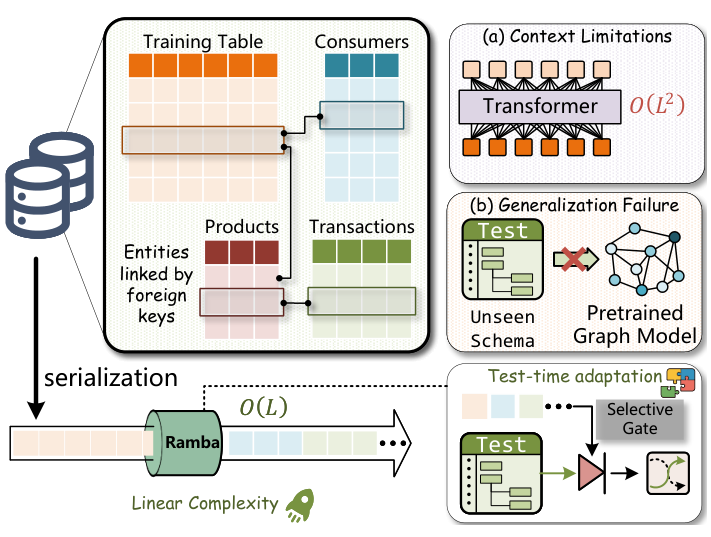
Figure 1:
Motivation for Ramba. (a) Transformers suffer from O(L2) complexity, limiting context capacity. (b) Pretrained graph models fail on unseen schemas. Ramba addresses both challenges via O(L) serialization and schema dynamic gating.
Abstract:
Relational Deep Learning aims to learn directly on multi-table databases, yet current methods face a fundamental tension: Transformers' quadratic complexity prohibits the large contexts that relational data demands, while GNNs sacrifice global context for efficiency. We introduce Ramba, the first selective state-space model for relational databases. Our approach features two key innovations: (1) Topology-Aware Linearization, which processes cells via global columnar serialization in linear complexity while recovering relational structure through sparse entity and foreign-key attention masks; and (2) Schema Dynamic Gating, which modulates SSM state transitions based on semantic alignment between the currently scanned attribute and the prediction target, enabling cross-table relevance filtering without relying on value distributions. Together, these mechanisms allow Ramba to ingest vast relational contexts while selectively retaining semantically relevant information. Experiments demonstrate state-of-the-art performance with linear scalability across diverse relational benchmarks.
Source Code: https://github.com/ROOOOOOOOL/Ramba
Figures:
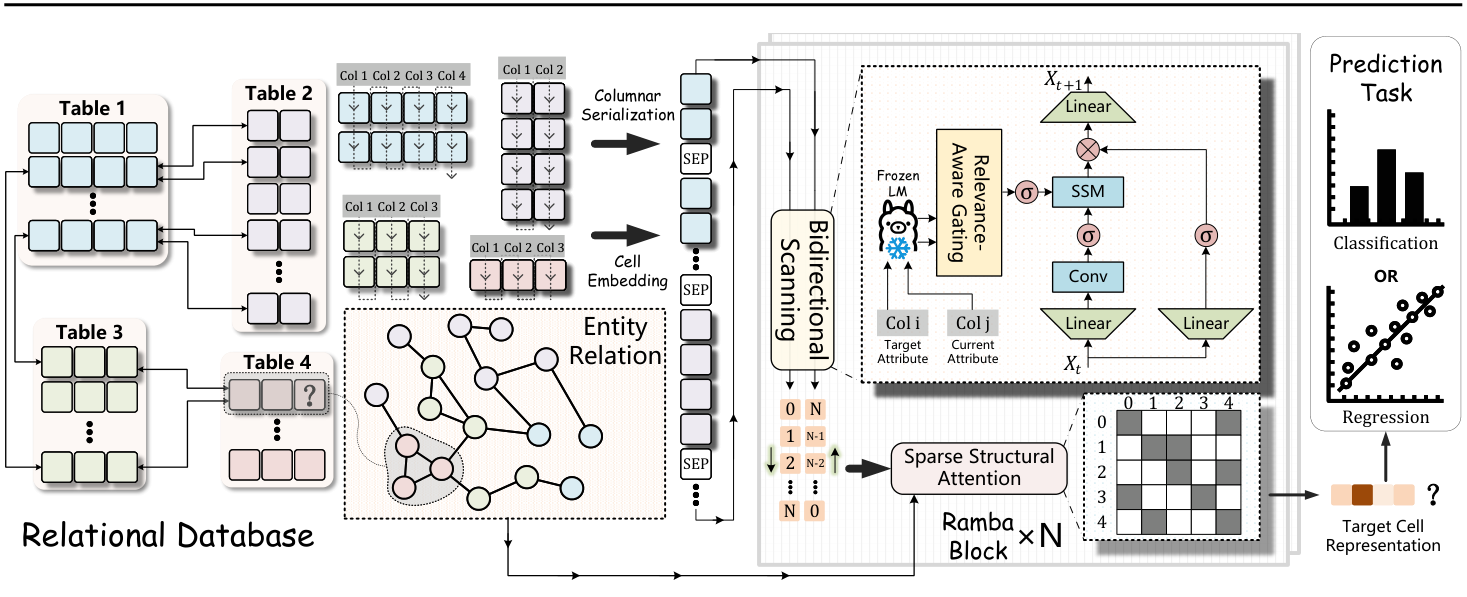
Figure 2: Ramba Architecture. A relational database is serialized column-by-column with [SEP] tokens, then processed by stacked Ramba blocks. Each block applies bidirectional scanning with Schema Dynamic Gating followed by Sparse Structural Attention (intra-entity and relational masks). The target cell representation is decoded for classification or regression.
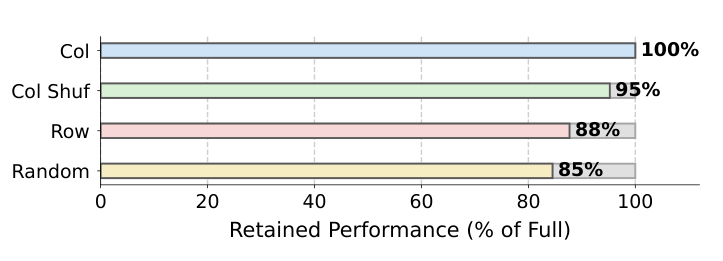
Figure 3: Serialization ablation. Column-wise serialization achieves the best performance (100%), while within-column shuffled ordering retains 95%, row-wise ordering drops to 88%, and fully random ordering falls to 85%. This confirms that the column-first inductive bias is important for capturing attribute-wise distributional patterns.
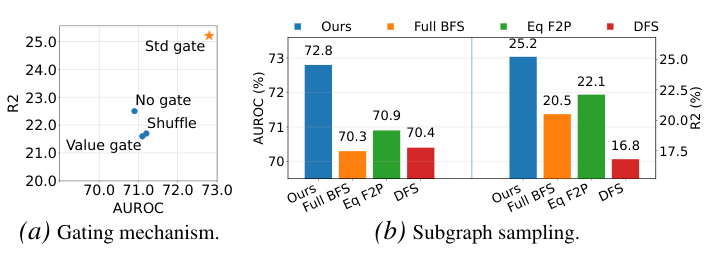
Figure 4: Ablation studies. (a) Gating mechanism: Schema-based gating achieves the best AUROC–R2 trade-off; incorrect semantic alignment (Shuffle) is more harmful than no gating, showing the mechanism actively exploits schema information. (b) Subgraph sampling: Width-limited BFS with foreign-key prioritization consistently outperforms full BFS, equal-priority BFS, and DFS.
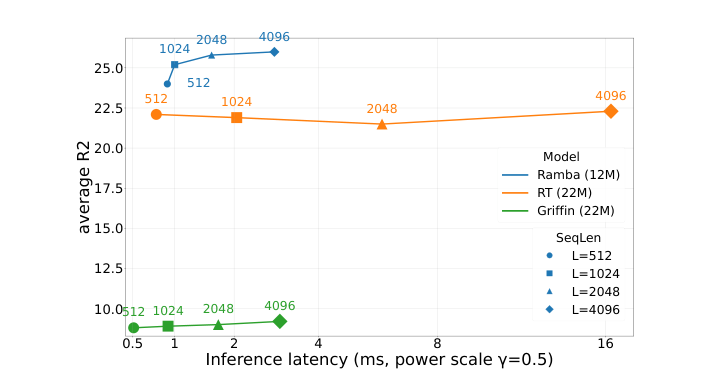
Figure 5: Long-context scaling analysis. Speed (tokens/sec) vs. accuracy trade-off across context lengths {512, 1024, 2048, 4096}. Ramba occupies the Pareto-optimal region: it achieves the highest accuracy at each context length while maintaining substantially lower latency than RT. At 4096 tokens, Ramba processes sequences 5.7× faster than RT while achieving +3.7% higher R2.
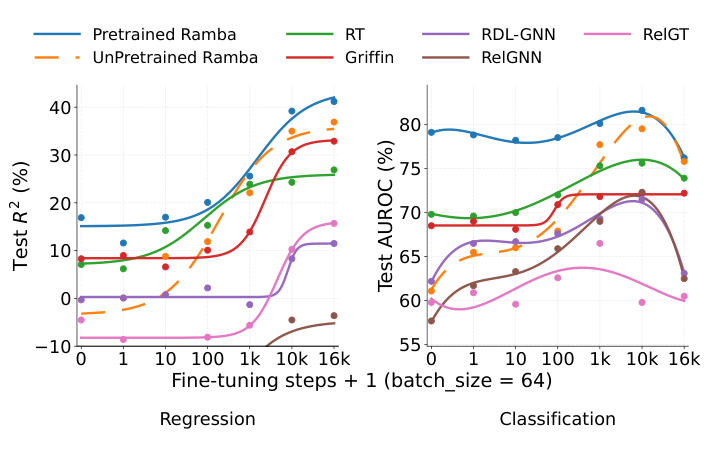
Figure 6: Few-shot fine-tuning dynamics. Test performance over training steps (log scale) for regression (R2) and classification (AUROC). Ramba's pretrained representations exhibit stronger initialization—zero-shot performance already exceeds most baselines' converged performance—and faster convergence, reaching 75% AUROC within 1k steps while RT requires 10k+ steps.
Materials:
 |
| Paper (PDF) |
Acknowledgements:
This work is supported in part by the Fundamental and Interdisciplinary Disciplines Breakthrough Plan of the Ministry of Education of China under contract No. JYB2025XDXM702, in part by Natural Science Foundation of China (NSFC) under contract No. 62506366 and 62572268, and in part by Ministry of Science and Technology of China under contract No. 2024YFB2809103.