GFMTuner: Test-Time Search for Automated GFM Fine-Tuning
Wenji Hu1
Xianan Wang1
Chunyu Wei1
Senhao Liu1
Kuien Liu2,3
Yunhai Wang1
Yueguo Chen1
1Renmin University of China
2Hefei University of Technology
3Institute of Software, Chinese Academy of Sciences
Accepted by KDD 2026
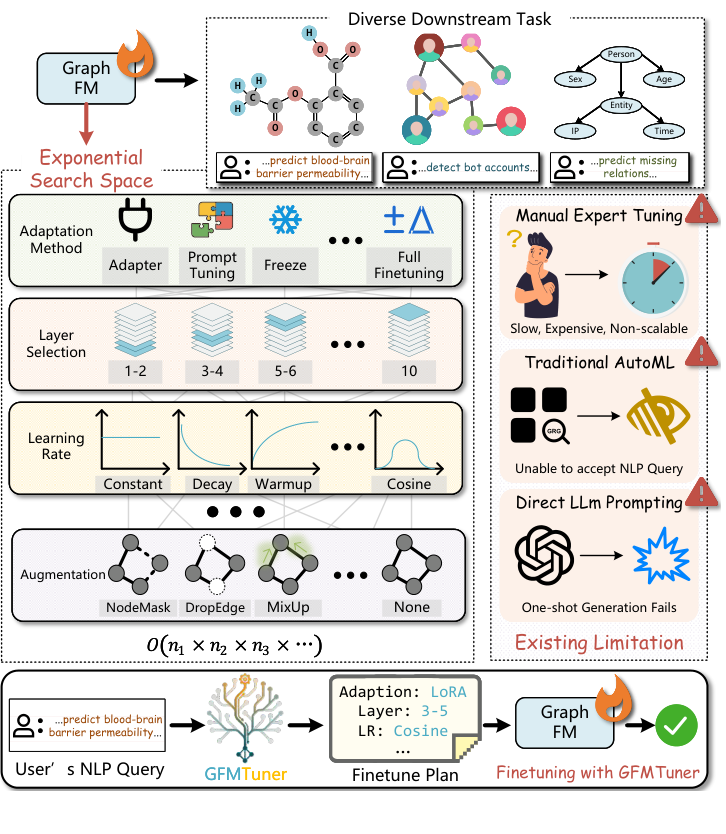
Figure 1:
Overview of GFMTuner. Top: A pre-trained GFM must be adapted to diverse downstream tasks. Middle: The fine-tuning decision space is exponentially large; existing approaches fail to address this complexity. Bottom: GFMTuner enables users to specify tasks via natural language and automatically generates effective fine-tuning strategies through test-time search, delivering deployment-ready models.
Abstract:
Graph Foundation Models (GFMs) have emerged as a powerful paradigm for learning transferable graph representations, yet adapting them to downstream tasks requires navigating an exponentially large decision space, traditionally demanding heavy expert effort. We propose GFMTuner, a framework that automates GFM fine-tuning by combining Large Language Model (LLM) agents with Monte Carlo Tree Search. GFMTuner accepts natural language task descriptions and generates effective fine-tuning strategies through test-time search. We introduce the Graph-Instructed Actor, which equips the LLM with graph analysis tools to ground action generation in structural insights, and Gradient Consistency, a self-supervised reward that measures gradient alignment across perturbed executions for efficient strategy evaluation. Experiments across diverse graph domains demonstrate that GFMTuner matches or exceeds human expert designs while reducing effort from weeks to a single natural language query.
Source Code: https://github.com/GFMTuner/GFMTuner
Figures:
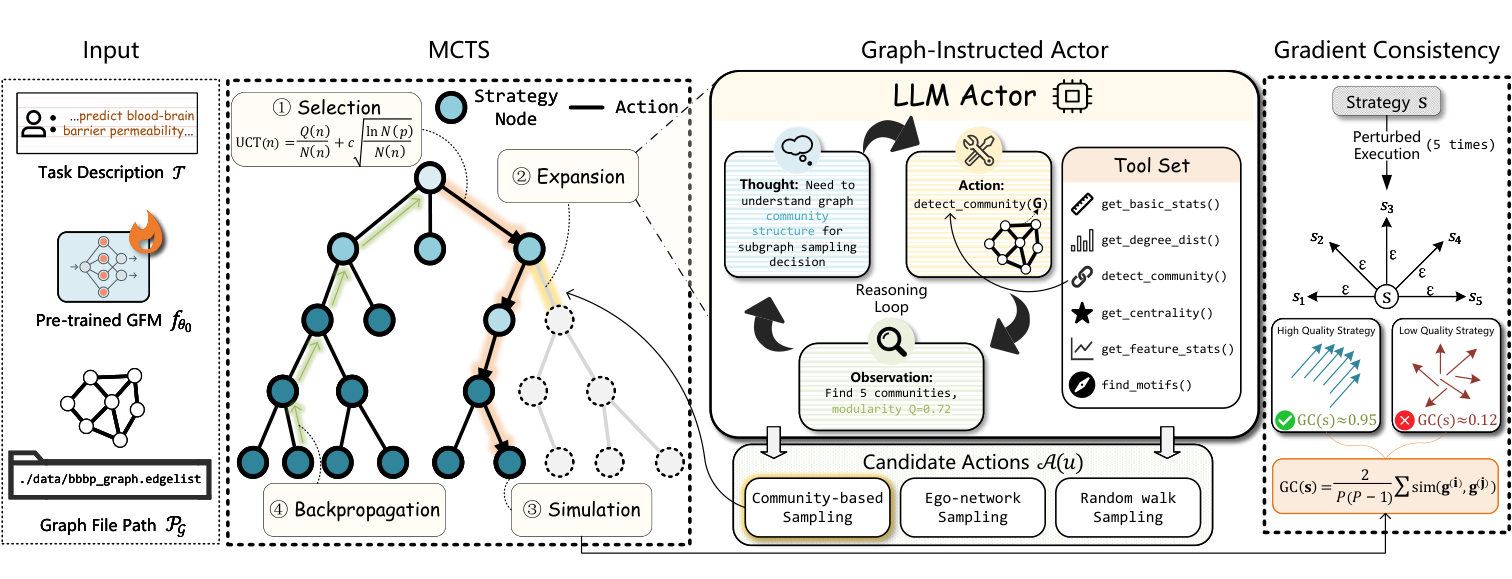
Figure 2: Overall framework of GFMTuner. Given a task description, a pre-trained GFM, GFMTuner employs MCTS to explore the fine-tuning strategy space. During expansion, the Graph-Instructed Actor reasons about graph properties via tool invocation to generate informed candidate actions. Complete strategies are evaluated using Gradient Consistency, which measures gradient alignment across perturbed executions to distinguish high-quality from low-quality strategies.
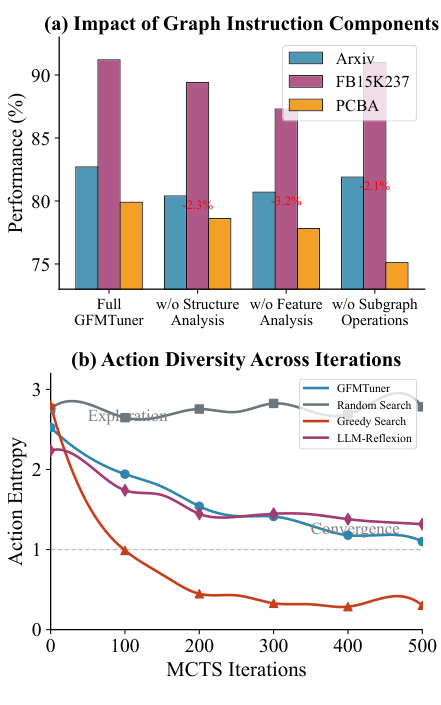
Figure 3: GIA analysis. (a) Impact of Graph Instruction Components: contribution of structure analysis, feature analysis, and subgraph operations to overall performance. (b) Action Diversity Across Iterations: GFMTuner maintains high entropy in early iterations for exploration, then gradually converges to promising regions, in contrast to random search and greedy search.
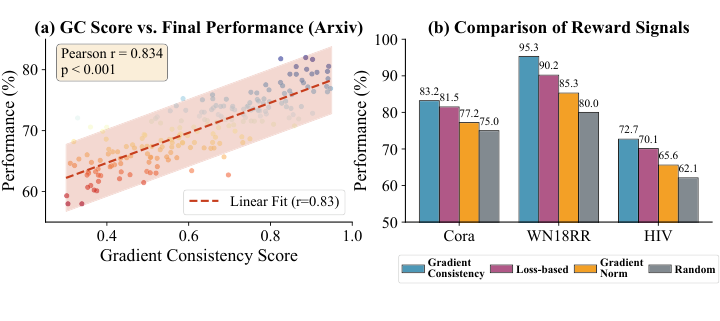
Figure 4: Analysis of Gradient Consistency. (a) Correlation between early-stage GC scores and final performance across 200 sampled strategies on Arxiv. (b) Performance comparison of different reward signals.
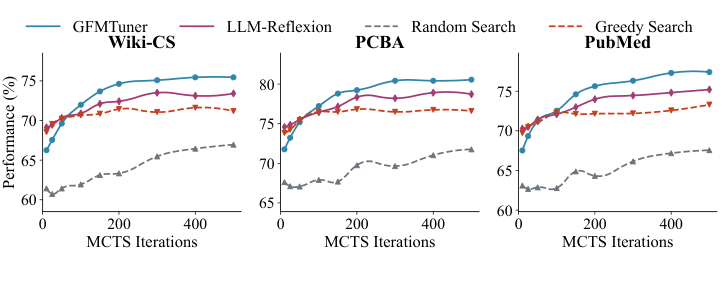
Figure 5: Performance vs. search budget (MCTS iterations). GFMTuner exhibits desirable anytime behavior: it quickly reaches competitive performance within 100 iterations and continues to improve with additional budget, while random search shows slow improvement and greedy search plateaus early.
Materials:
 |
| Paper (PDF) |
Acknowledgements:
This work was supported by the National Key R&D Program of China (No. 2023YFC3304701), the National Natural Science Foundation of China (NSFC) under contract No. 62506366, the Open Project of the Xinjiang Key Laboratory of Multimodal Intelligent Computing and Large Models, Kashi University, and the Big Data and Responsible Artificial Intelligence for National Governance, Renmin University of China.