Decentralized Actor Scheduling and Reference-based Storage in Xorbits: a Native Scalable Data Science Engine
Weizheng Lu1
Chao Hui2
Yunhai Wang1
Feng Zhang1
Yueguo Chen1
Bao Liu3
Chengjie Li3
Zhaoxin Wu3
Xuye Qin3
1Renmin University of China
2Shandong University
3Xorbits Inc.
Accepted by VLDB 2025
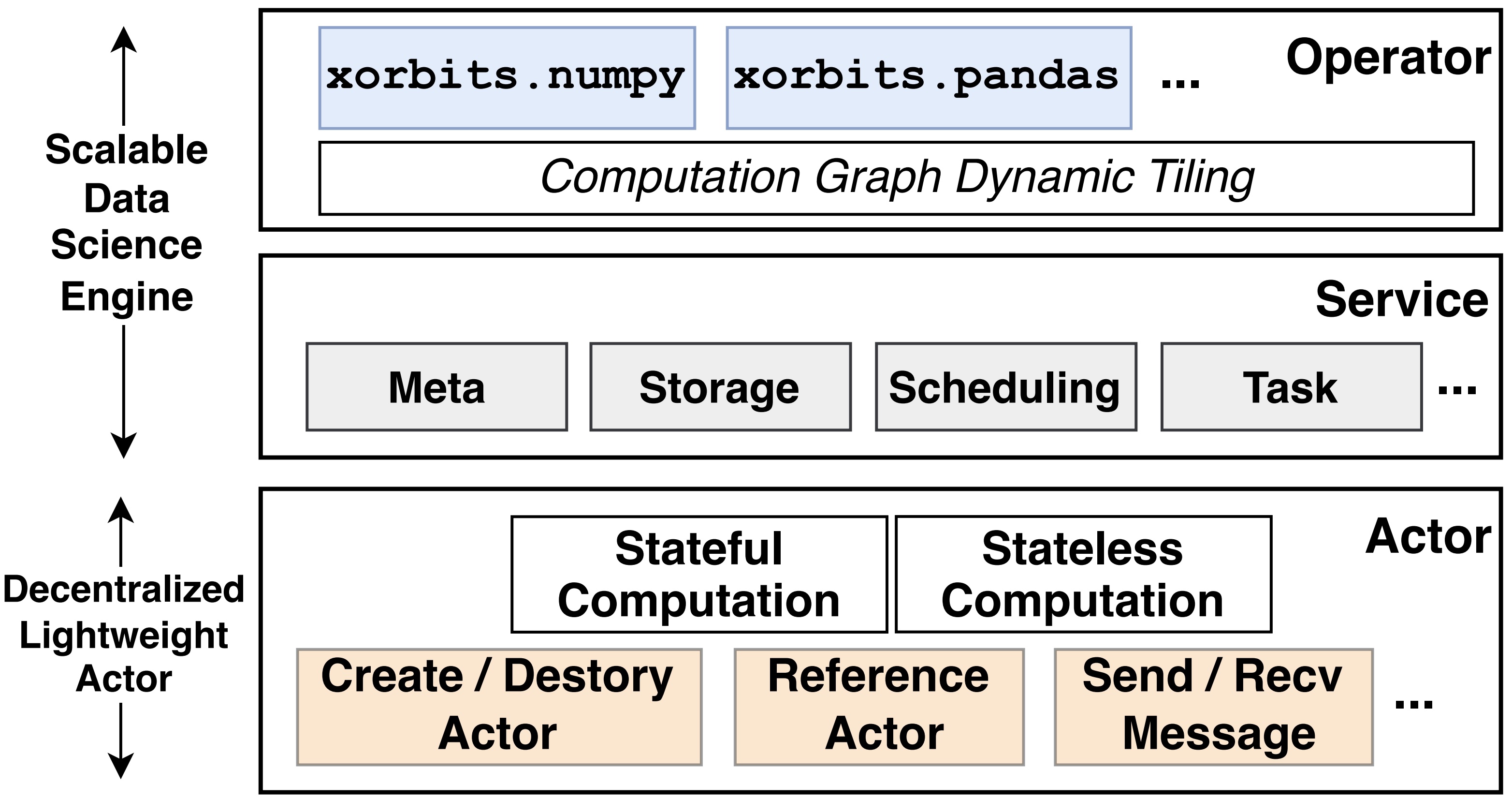
Figure 3:
Xorbits system architecture: divided into the decentralized decentralized actor layer and the scalable data science engine layer.
Abstract:
Data science pipelines consist of data preprocessing and transformation, and a typical pipeline comprises a series of operators, such as DataFrame filtering and groupby. As practitioners seek tools to handle larger-scale data while maintaining APIs compatible with popular single-machine libraries (e.g., pandas), scaling such a pipeline requires efficient distribution of decomposed tasks across the cluster and fine-grained, key-level intermediate storage management, two challenges that existing systems have not effectively addressed. Motivated by the requirements of scaling diverse data science applications, we present the design and implementation of Xorbits, a native scalable data science engine built on our decentralized actor model, Xoscar. Our actor model can eliminate dependency on a global scheduler and enable fast actor task scheduling. We also provide reference-based distributed storage with unified access across heterogeneous memory resources. Our evaluation demonstrates that Xorbits achieves up to 3.22× speedup on 3 machine learning pipelines and 22 data analysis workloads compared to state-of-the-art solutions. Xorbits is available on PyPI with nearly 1k daily downloads and has been successfully deployed in production environments.
Source code: Xorbits, Xoscar
Figures:
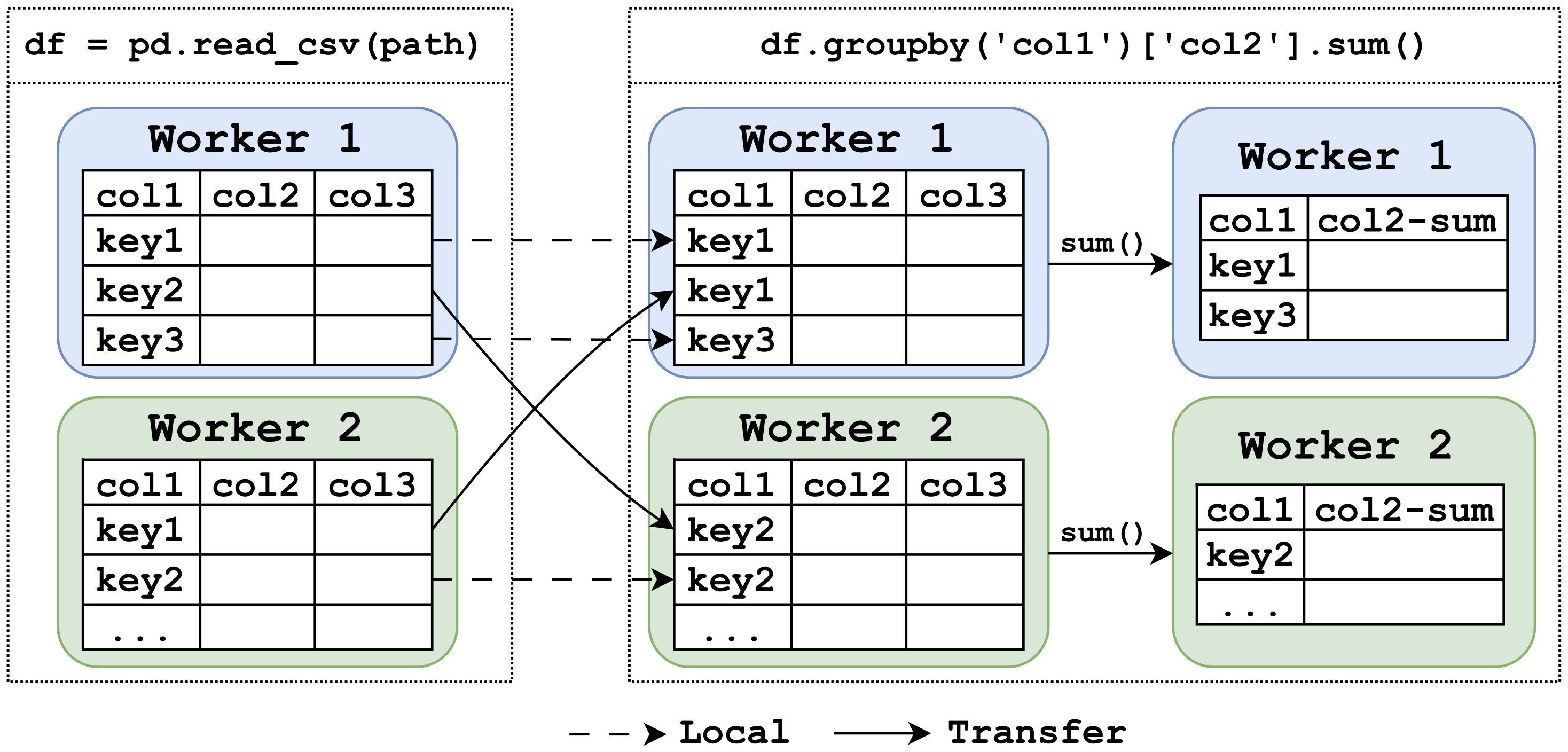
Figure 1: A simple data science pipeline in a distributed environment: loading data followed by a column-wise groupby. Note that this diagram provides a simplified illustration and does not show the complete MapReduce workflow.
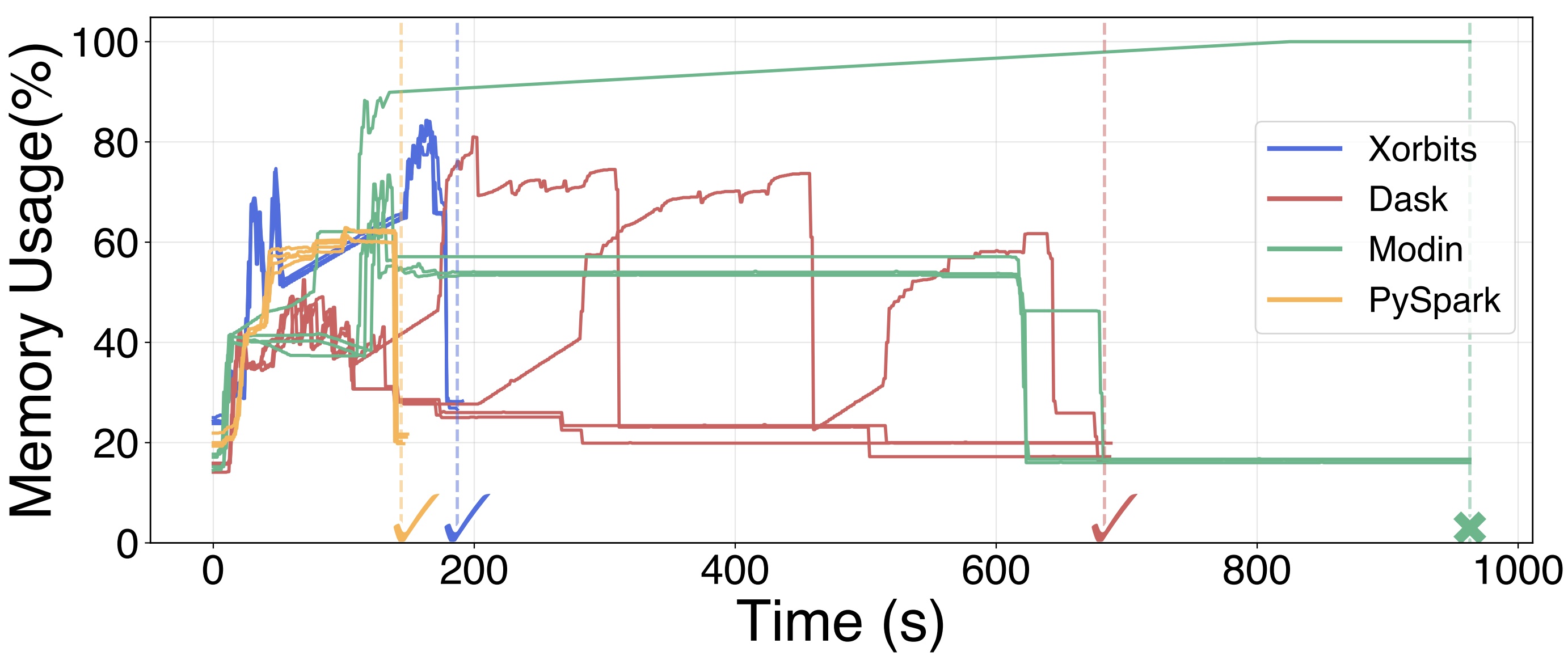
Figure 2: Memory usage during distributed DataFrame groupby on four workers using Xorbits, Dask, PySpark, and Modin on Ray. Each line represents one worker’s memory usage over time.
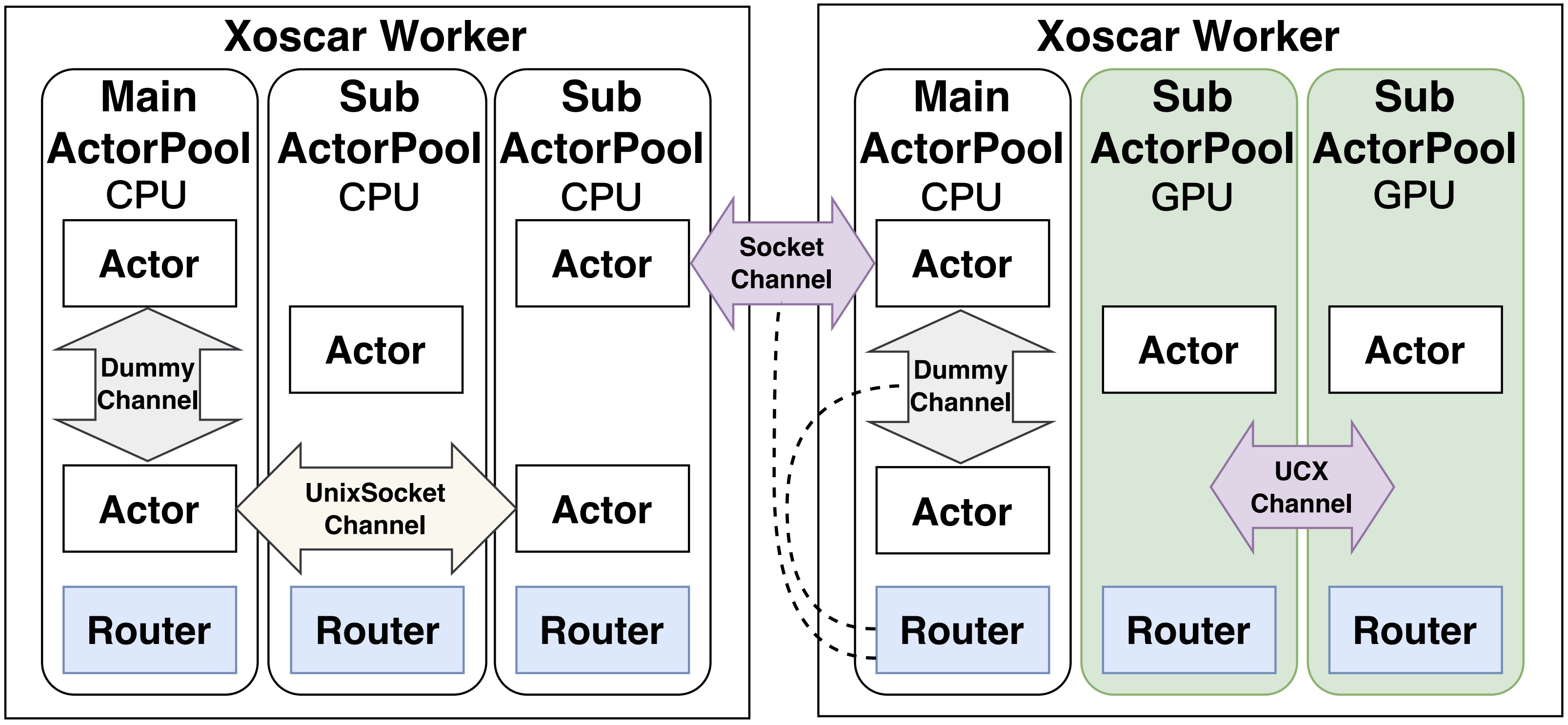
Figure 4: Xoscar architecture.
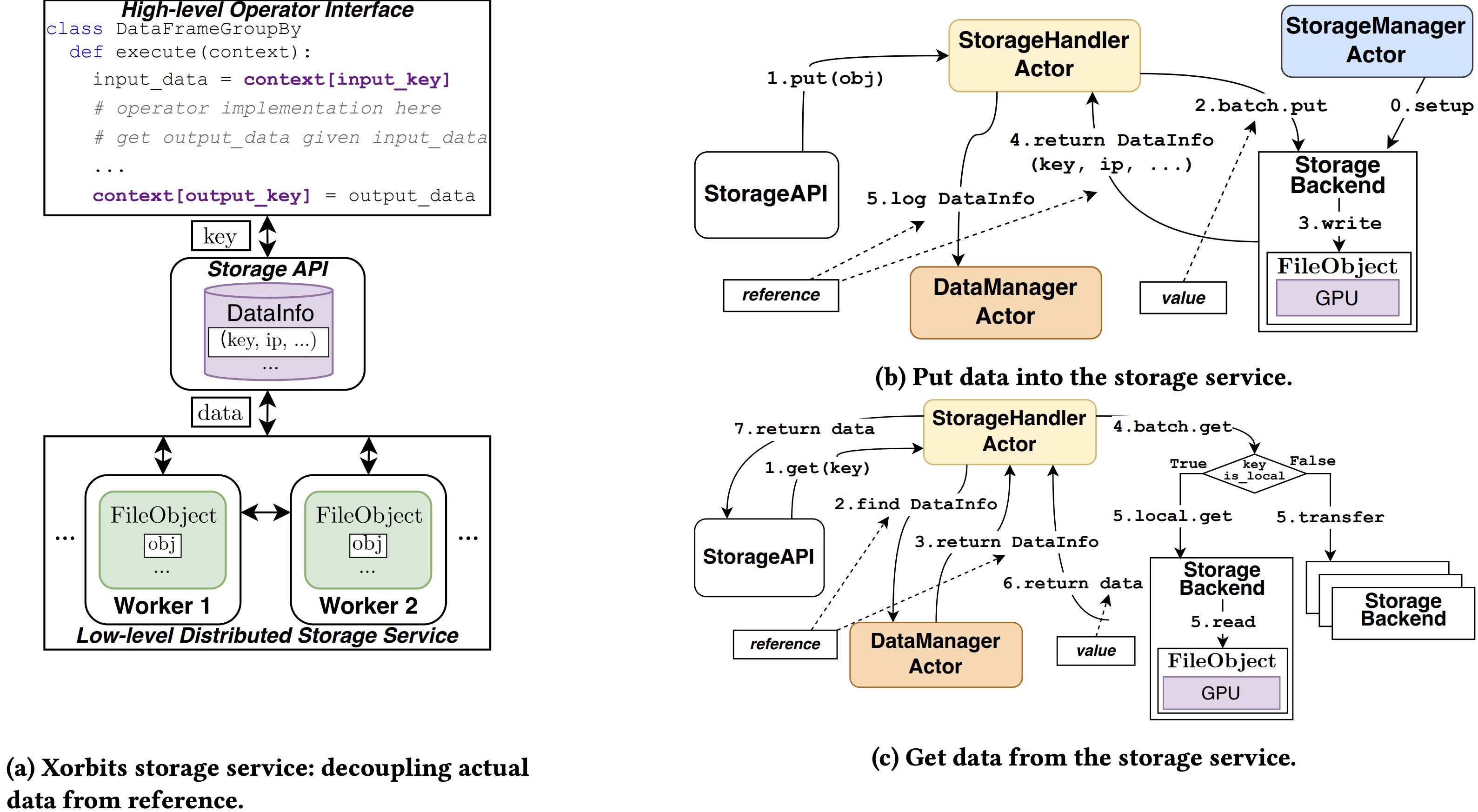
Figure 5: Xorbits storage: from operator implementation to distributed data access.
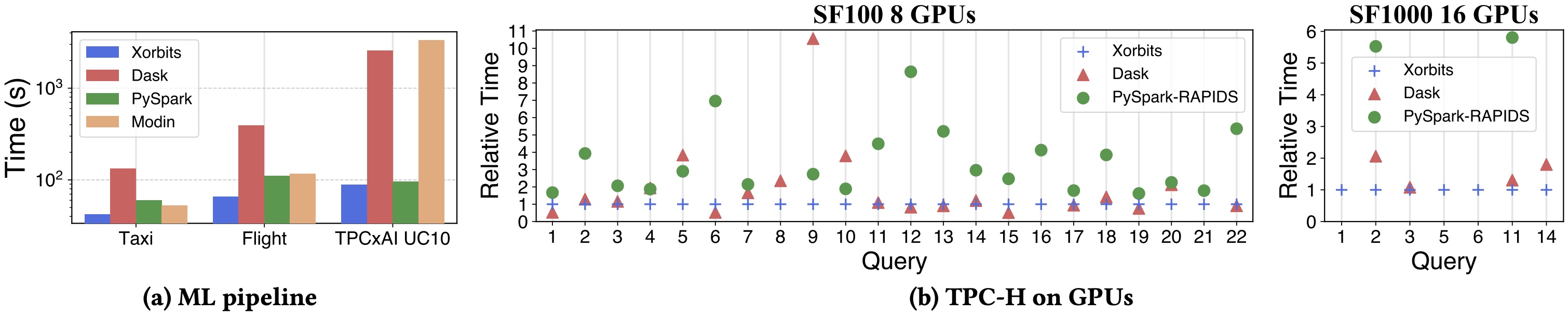
Figure 6: End-to-end workloads performance.
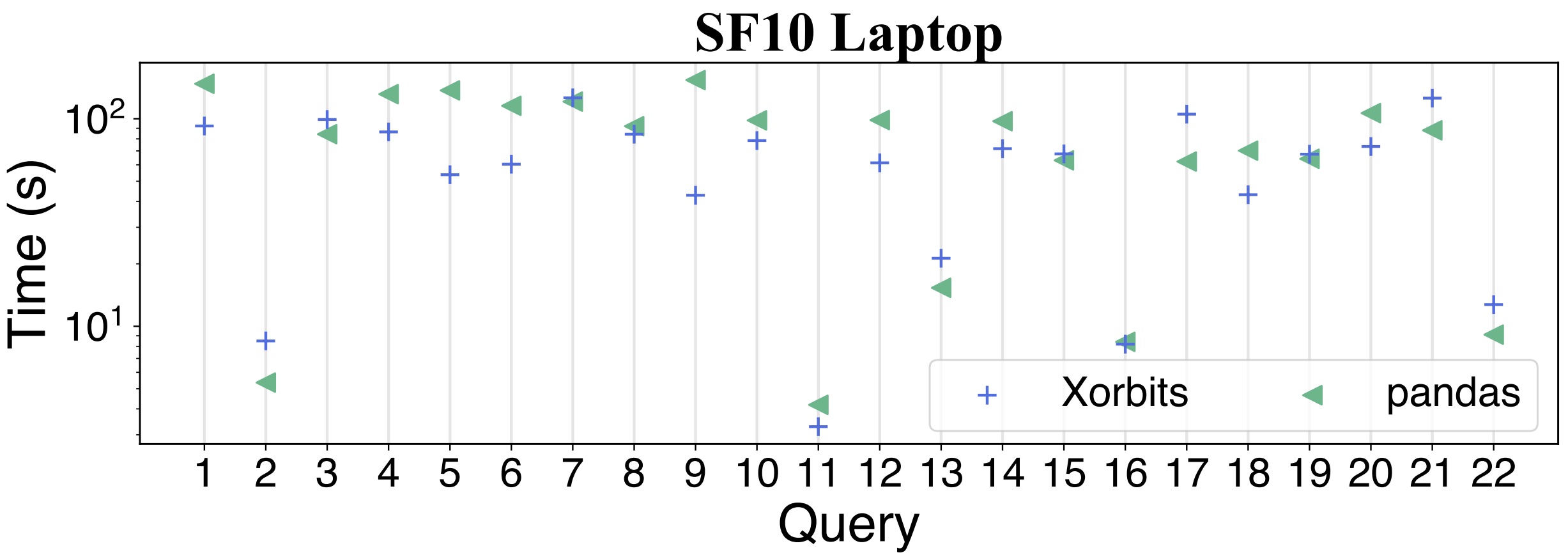
Figure 7: Compare Xorbits with underlying pandas to test potential overhead introduced by Xorbits.
Materials:

|
| Paper (917K) |
Acknowledgements:
This work is supported by the grants of the National Key R&D Program of China under Grant 2022ZD0160805, NSFC (No.62132017 and No.U2436209), the Shandong Provincial Natural Science Foundation (No.ZQ2022JQ32), the Beijing Natural Science Foundation (L247027), the Fundamental Research Funds for the Central Universities, and the Research Funds of Renmin University of China.